

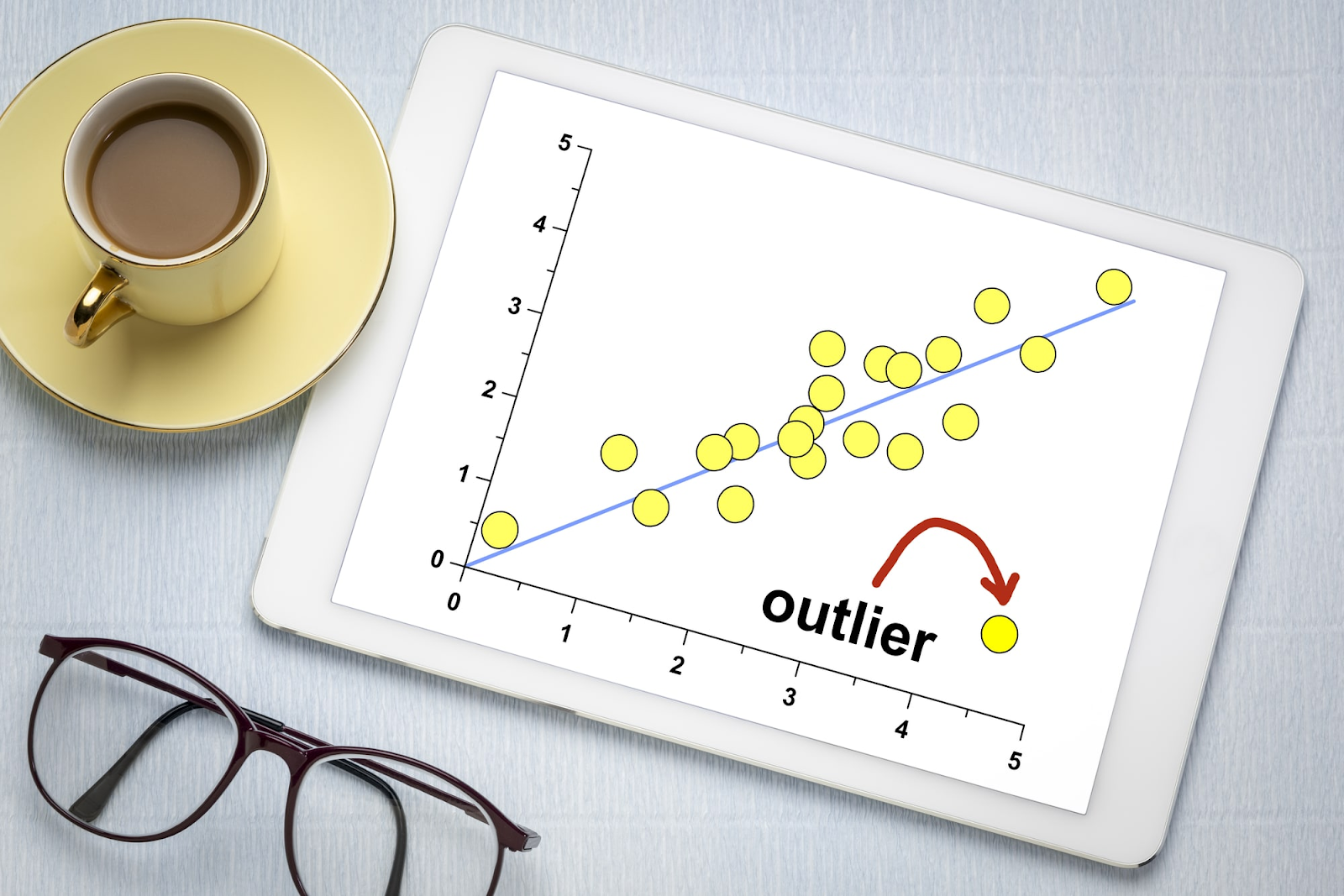
Outliers, ou dados específicos fora da curva, são pontos atípicos em um conjunto de dados que diferem significativamente dos demais valores. Eles podem surgir devido a erros de medição, falhas nos processos de coleta, ou até mesmo serem representações genuínas de eventos raros e extremos.
Embora possam conter informações valiosas, os outliers também têm o potencial de distorcer análises estatísticas e modelos preditivos se não forem tratados adequadamente. Neste artigo, explicaremos como identificar os dados fora da curva e as estratégias mais eficazes para lidar com eles, confira!
Compreendendo dados outliers
Como já definimos, os outliers são observações que se desviam significativamente da distribuição geral de um conjunto de dados. Essas discrepâncias podem ser tanto de valores muito altos, quanto muito baixos em relação à média dos dados.
Para entender melhor, considere um conjunto de dados que representa a idade de um grupo de pessoas, e dentre elas, há uma pessoa com 150 anos. Esse valor se torna um outlier, pois é extremamente raro e diverge substancialmente da idade média do grupo.
Várias razões podem levar à existência de outliers em conjuntos de dados:
- Erros de medição: Falhas no processo de coleta ou registro de dados podem gerar valores incorretos, resultando em outliers artificiais;
- Eventos raros: Em alguns casos, os dados fora da curva representam eventos genuinamente incomuns, como desastres naturais ou incidentes extraordinários;
- Variações na população: Em estudos que envolvem diferentes grupos ou subpopulações, é possível que os dados desses grupos apresentem comportamentos distintos, levando à presença de outliers;
- Falhas no sistema: Em sistemas de monitoramento, uma falha ou mau funcionamento pode levar a leituras extremas e, portanto, a outliers.
Os outliers podem ser encontrados em diversas áreas. Vejamos alguns exemplos:
- Finanças: No mercado financeiro, um evento excepcional, como uma grande recessão econômica, pode gerar um outlier nos dados de desempenho das ações;
- Saúde: Na área médica, um paciente com uma resposta atípica a um tratamento é considerado como um outlier nos resultados do estudo;
- Ciências sociais: Em pesquisas sociológicas, pode haver respostas inesperadas que se afastam do padrão geral dos entrevistados;
- Indústria: Em processos de fabricação, um defeito grave em um produto é registrado como um outlier na qualidade dos itens produzidos.
Métodos para identificar dados outliers
A identificação de outliers é uma etapa crucial no tratamento de dados, e várias abordagens podem ser empregadas.
Visualização de dados
Gráficos de dispersão, box plot e histogramas são ferramentas úteis para identificar dados fora da curva visualmente. No gráfico de dispersão, os outliers são pontos isolados que se afastam consideravelmente do agrupamento geral dos dados.
Já o box plot é capaz de mostrar valores extremos por meio de “bolinhas” posicionadas fora das “caixas” que representam os quartis do conjunto de dados. Histogramas, por sua vez, permitem identificar regiões com baixa densidade de ocorrências, que indicam a presença de outliers.
Análise estatística
A análise estatística oferece métodos mais quantitativos para identificar outliers:
- Desvio padrão: Outliers são frequentemente definidos como valores que se encontram a uma distância maior que três desvios padrão da média. No entanto, essa abordagem pode ser sensível a conjuntos de dados com distribuições não normais;
- Z-score: O Z-score é a medida de quantos desvios padrão um ponto está afastado da média. Valores com Z-score acima de um limite estabelecido podem ser considerados outliers;
- IQR (Intervalo Interquartil): O IQR é a diferença entre o terceiro quartil (Q3) e o primeiro quartil (Q1) de um conjunto de dados. Dessa maneira, define-se outliers como valores que estão acima de Q3 + 1,5 * IQR ou abaixo de Q1 – 1,5 * IQR.
Ferramentas e softwares para detecção automática de dados outliers
Atualmente, existem várias ferramentas e bibliotecas em linguagens de programação como Python e R que permitem identificar outliers automaticamente. Alguns exemplos populares incluem o scikit-learn (Python), o pandas (Python) e o caret (R).
Impacto dos outliers na análise de dados
Os outliers influenciam drasticamente as métricas estatísticas, como a média e o desvio padrão, que são altamente sensíveis a valores extremos. Isso pode levar a conclusões equivocadas e decisões mal informadas se não forem tratados adequadamente.
A média é particularmente sensível a outliers, pois é calculada somando todos os valores e dividindo pelo número de observações. Portanto, um único valor extremo aumenta ou diminui significativamente a média. Já a mediana é menos afetada por outliers, pois é o valor central de um conjunto de dados ordenado.
Em modelos de machine learning, os outliers são interpretados como pontos de grande importância, resultando em modelos menos precisos e generalizados. Além disso, eles também influenciam os coeficientes de um modelo de regressão, prejudicando a capacidade de fazer previsões precisas.
Estratégias para lidar com dados outliers
Quando se trata de lidar com outliers, é importante considerar a natureza dos dados e o contexto do problema em questão:
Remoção de dados outliers: quando é apropriado?
A remoção de dados fora da curva é uma estratégia válida, mas deve ser realizada com cuidado. A exclusão de dados reduz o tamanho da amostra e, em alguns casos, leva a conclusões enviesadas. Essa abordagem é mais apropriada quando há certeza de que os outliers são resultados de erros ou anomalias e não representam informações cruciais para a análise.
Transformação de dados: normalização, padronização
Em alguns casos, é possível aplicar transformações matemáticas nos dados para reduzir o impacto dos outliers. Por exemplo, a normalização ou padronização dos dados auxilia a tornar a distribuição mais simétrica, diminuindo a influência de valores extremos.
Substituição de outliers por valores centrais ou valores previstos
Outra abordagem é substituir os valores outliers por medidas de tendência central, como a média ou a mediana, ou mesmo por valores previstos por um modelo de machine learning. Essa técnica ajuda a manter o tamanho da amostra e suavizar o impacto dos dados fora da curva nos resultados.
Melhores práticas para prevenir e lidar com dados outliers
Para prevenir a ocorrência de outliers e lidar com eles de maneira eficaz, é importante seguir algumas boas práticas:
- Garanta que os procedimentos de coleta de dados sejam bem definidos e consistentes, reduzindo a possibilidade de erros e anomalias;
- Defina critérios claros para identificar outliers com base no contexto do problema e na análise exploratória dos dados. Isso ajuda a evitar decisões subjetivas;
- Mantenha um monitoramento constante dos dados ao longo do tempo para identificar novos outliers ou mudanças significativas no comportamento deles.
Como você pode notar, a identificação correta dos outliers e a aplicação de estratégias adequadas para lidar com eles são essenciais para garantir a precisão e a confiabilidade dos resultados. Ao seguir as melhores práticas e utilizar métodos apropriados, os profissionais de análise de dados obtêm insights mais confiáveis e valiosos.
Ainda ficou com alguma dúvida? Entre em contato com a Yooper, somos especialistas em desenvolver estratégias inteligentes para um mundo digital em evolução, ajudando seu negócio a atingir o máximo potencial!
